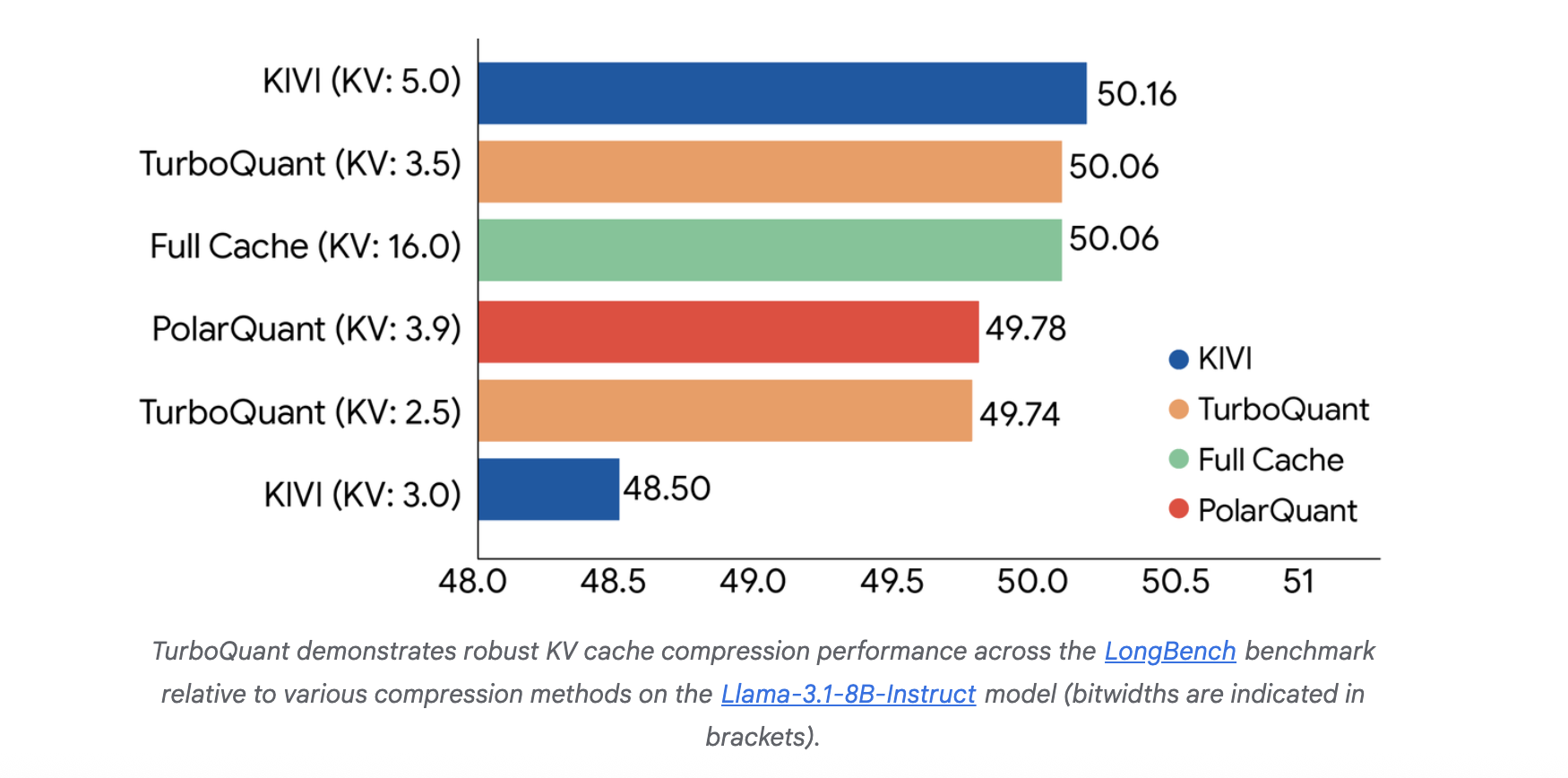
Google Introduces TurboQuant: A New Compression Algorithm that Reduces LLM Key-Value Cache Memory by 6x and Delivers Up to 8x Speedup, All with Zero Accuracy Loss
The scaling of Large Language Models (LLMs) is increasingly constrained by memory communication overhead between High-Bandwidth Memory (HBM) and SRAM. Specifically, the Key-Value (KV) cache size sc...
Source: MarkTechPost
The scaling of Large Language Models (LLMs) is increasingly constrained by memory communication overhead between High-Bandwidth Memory (HBM) and SRAM. Specifically, the Key-Value (KV) cache size scales with both model dimensions and context length, creating a significant bottleneck for long-context inference. Google research team has proposed TurboQuant, a data-oblivious quantization framework designed to achieve near-optimal […] The post Google Introduces TurboQuant: A New Compression Algorithm that Reduces LLM Key-Value Cache Memory by 6x and Delivers Up to 8x Speedup, All with Zero Accuracy Loss appeared first on MarkTechPost.












![An inside look at a ConsenSys-funded web 3.0 accelerator [INTERVIEW]](https://cryptoslate.com/wp-content/uploads/2019/09/ethereum-space-social.jpg)